
Base64 Encoded Data Detection
Exfiltrated sensitive data can be difficult to discover by analyzing network traffic in real-time if it is first base64 encoded by attackers. It is typically not possible to attempt to identify and decode all possible base64 sequences from network traffic unless the encoding is specified in the protocol context. This hampers direct detection mechanisms such as keyword matches. However, when base64 encoded, any possible string may appear as one of three unique encoded offsets, due to the nature of the base64 6-bit alphabet. Using these three offsets and a YARA signature with Fidelis Elevate Network, it is possible to find encoded data within network traffic without first decoding all possible base64 encoded blocks.
Base64 Encoding and Decoding
Base64 is a binary-to-test encoding scheme where sequences of 24 bits can be represented by four 6-bit Base64 digits. Each 6-bit digit is then represented by a set of 64 unique 7-bit ASCII characters, from a pre-defined alphabet.
The standard Base64 alphabet is defined in RFC 4648, although alternative alphabets can be used.
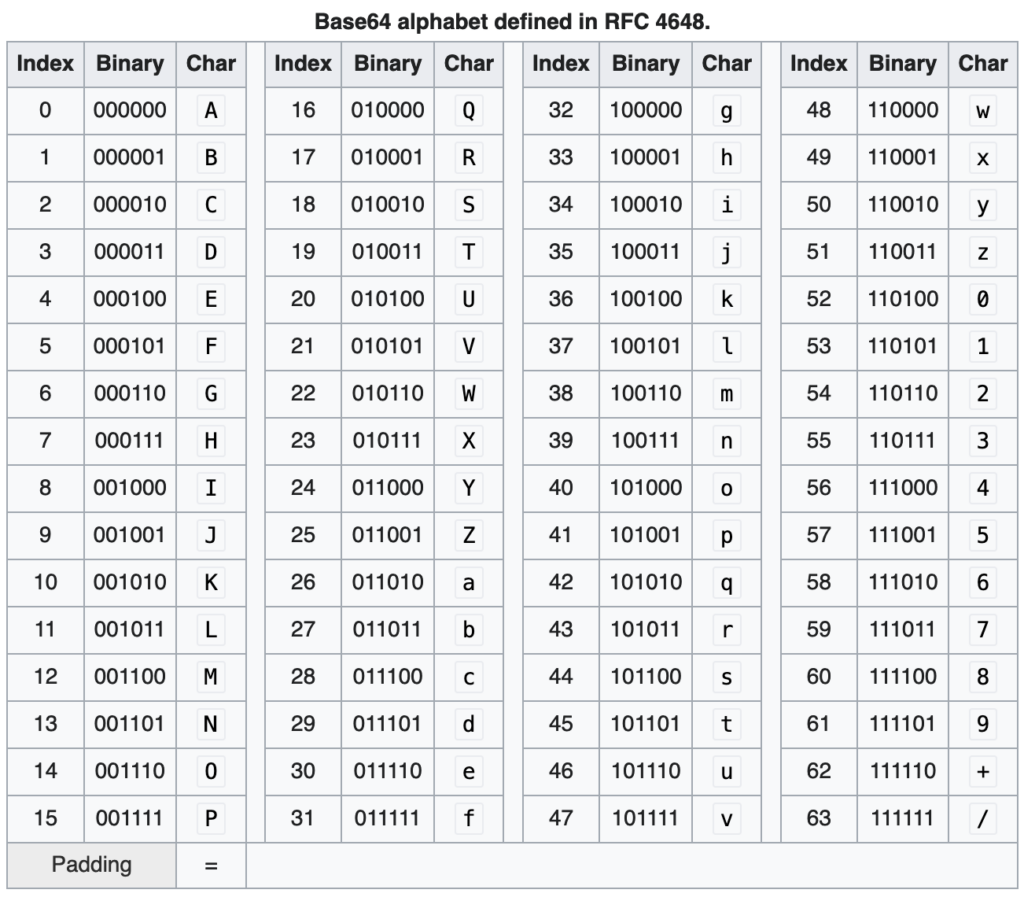
Figure 1: Base64 alphabet as defined in RFC 4648 (source: Wikipedia) [3]
In addition to the 64 possible characters, a one or two padding characters may be padded to the end of encoded sequences, in the case that the total number of non-decoded bits is not a multiple of 6. For example, the letter ‘A’ (hex: x41, binary: 0100 0001) does not break evenly into multiples of 6 but can be made to be by appending a pair of two 0-bits. The sequence then becomes 010000 01(00)(00), for a total of 12 bits, which is divisible by 6. The two 6-bit digits are encoded using the standard base64 alphabet to ‘QQ’. The extra pair of 2 padding bits is represented by adding two padding characters, for a final encoded result of ‘QQ==’.
When the encoding is reversed, the padding characters are removed, along with the extra pair of 2-bits. In this example, QQ== (010000 010000), becomes 01000001 or ‘A’. If only an additional two 0-bits are needed to make the total number of bits divisible by 6, then only a single padding character is added to the encoded sequence, and only two 0-bits are removed when the encoded is reversed.
Cyber Threat Exploiting Base64 Encryption
Attackers often use base64 to encode command and control communication, as well as to exfiltrate data, using both the standard alphabet as well non-standard alphabets. For example, a non-standard alphabet may be similar to the standard alphabet but the “+” and “/” characters may be substituted with “–“, “_” characters respectively and a “.” might be used for the padding character.
Base64 blocks can be difficult to identify in large amounts of network traffic, due to the variability of all possible encodings. Base64 encoded data may contain as many A-Z, a-z, 0-9 characters as needed and may or may not contain any +, / or padding characters at all. Also, it is typically not possible to try real-time Base64 decoding over all traffic to attempt to find exfiltrated sensitive data, unless the base64 encoding is indicated in the context of the transferring protocol, such as SMTP.
In addition to this difficulty, keywords, such as paths, filenames, user accounts, registry keys, or any other sensitive information are difficult to find in a base64 encoded sequence, even if it can be recognized, without first attempting to reverse the decoding.
For example, when the keyword “password” is base64 encoded, it encodes to “cGFzc3dvcmQ=”. However, when it is surrounded by other characters the encoding changes significantly. The string “QpasswordQ” encodes to “UXBhc3N3b3JkUQ==”, which is not at all like the stand-alone encoding. Worse yet, “QQpasswordQQ” becomes “UVFwYXNzd29yZFFR”, which is another set of characters entirely.
Finding keywords in Base64 Encoded Blocks
Is it possible then to find an encoded keyword without first detecting and decoding Base64? Given the example of the “password” keyword again, “QQQpasswordQQQ” becomes “UVFRcGFzc3dvcmRRUVE=”, which looks very similar to the standalone encoding “cGFzc3dvcmQ=”, although the “Q=” is no longer present, and the encoded sequence starts differently. “QQQQpasswordQQQQ” becomes “UVFRUXBhc3N3b3JkUVFRUQ==”, which is like the second “QpasswordQ” encoding, although again with some differences to the beginning and end.
If one keeps on going like this, by prepending and appending more characters to the keyword, it is found that only three possible different encodings for “password” exist, although with some differences in the beginning and the end of the encodings. This will be true for any encoded string, except for single characters.
For the string “password”, the three possible offsets that will be contained in any possible base64 encoding of that string, regardless of which characters are prepended or appended to the string are: “cGFzc3dvcm”, “Bhc3N3b3Jk”, and “wYXNzd29yZ”. Now, all that’s needed to find the string “password” in any set of random data is to find one of those three offsetes. The longer the searched data or keyword, the more confidence that it has been found in a base64 block when one of three possible encoded sequences has been matched.
For example, the following base64 encoded block contains the keyword “password” as indicated by the presence of the offset “cGFzc3dvcm”:
V2h5IGRpZCB0aGUgcGFzc3dvcmQgdGFrZSB1cCBnYXJkZW5pbmc/IEl0IGhlYXJkIHRoYXQncyB0aGUgYmVzdCB3YXkgdG8gY3VsdGl2YXRlIHN0cm9uZyByb290cyE
Detections Using Base64 Offsets
The CyberChef tool [2] (https://gchq.github.io/CyberChef), contains the “Show Base64 offsets” operation that will compute these three possible encoded strings. To use it, drag the operation to recipe and supply the searched keyword as input.
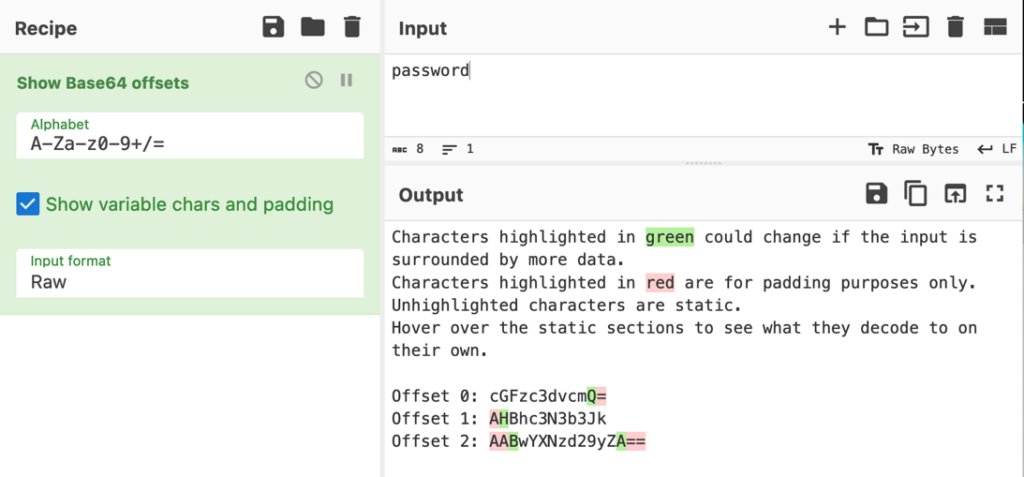
This operation even accepts different alphabets, although this needs to be known before pre-computing the offsets for a given keyword.
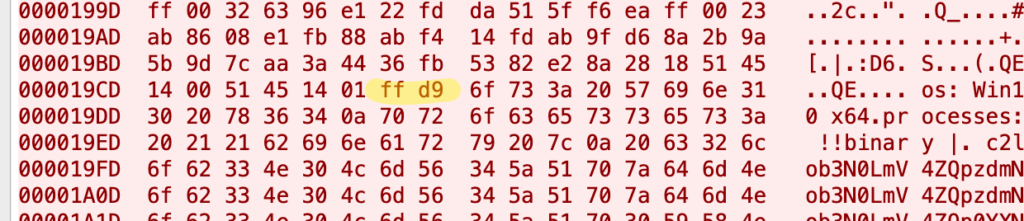
The packet capture in figure 3 is of an HTTP POST of a JPEG file with base blocks of Base64 encoded data after the End-of-Image marker (0xFF 0xD9) [1]. In this data, there are also unencoded headings such as, os, processes, hdd, build, network, cmd_id, which indicate that there is system profile data contained within the encoded blocks.
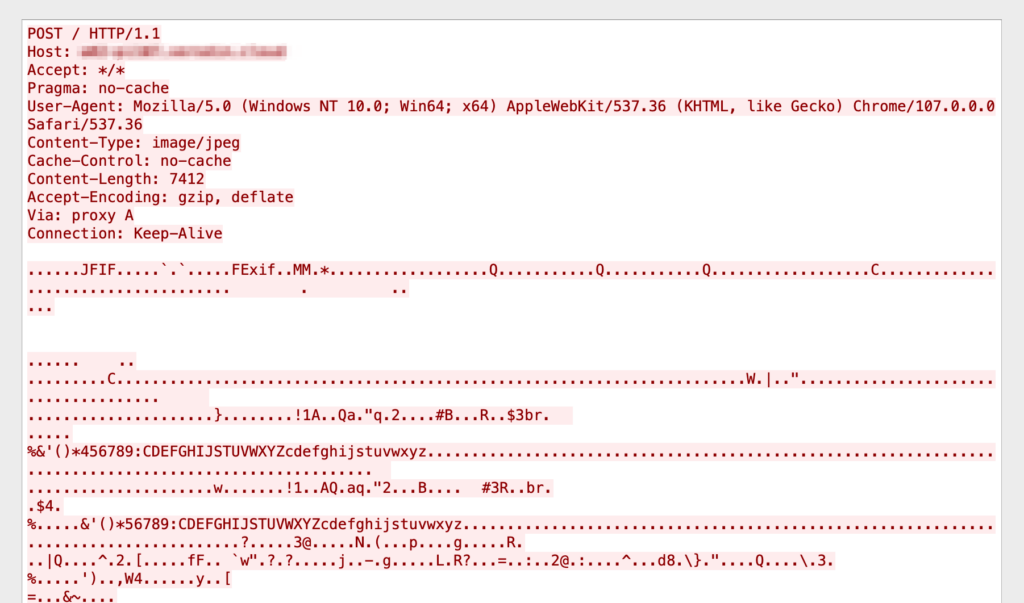
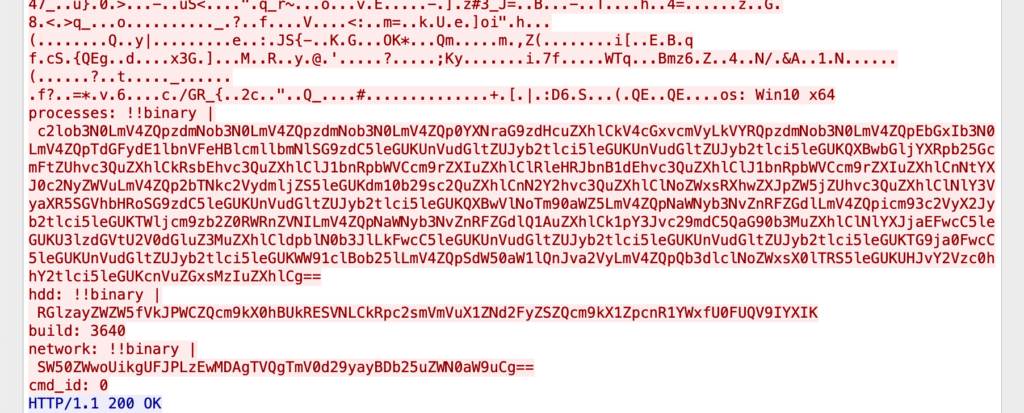
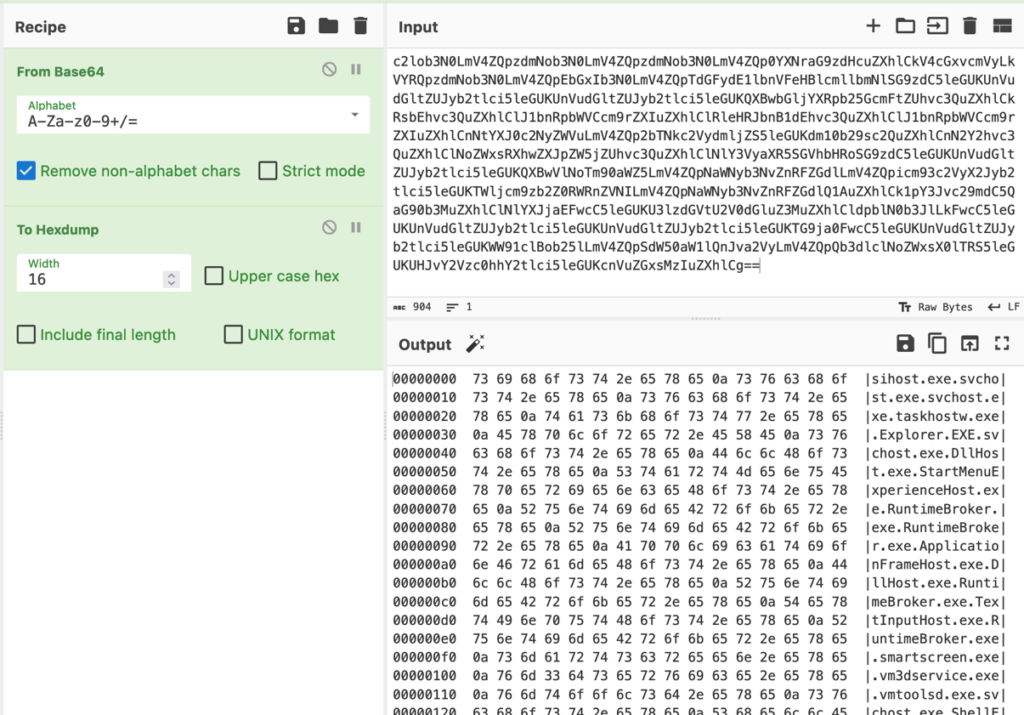
Using CyberChef to decode the largest encoded block, we see that it is an encoded list of executables. Given that the block appears after the “processes” heading, we can surmise that this is a list of processes running on an infected system.
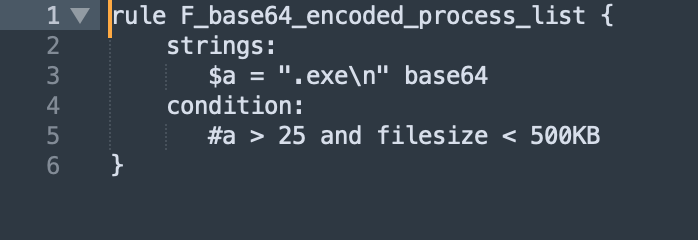
Using Base64 offsets, detecting a base64 encoded list of processes running on an infected system is straightforward. To detect an encoded process list, look for multiple instances of the offsets for the string “.exe” followed by a new line character (0x0A). YARA string matching has implemented a base64 modifier for string matches that will do this automatically [4], as shown in Figure 6:
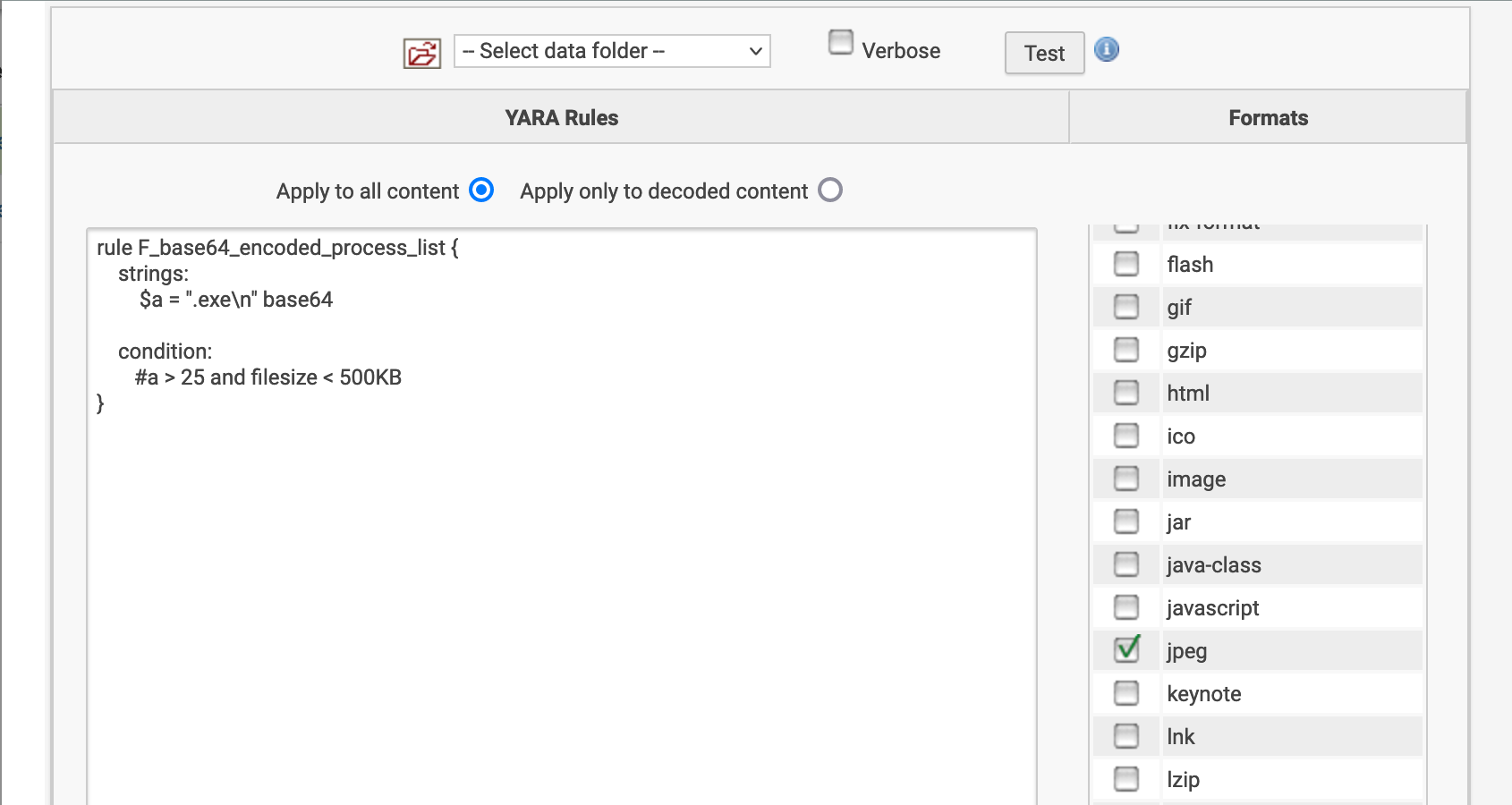
Concerns about false positives are minimized by requiring that those specific encoded offsets, although only 6 characters each, appear at least 25 times in a file of 500KB or less. The offsets are random enough that it is not likely to find that many occurrences in a single encoded context unless they are there deliberately. If they are found, it is a good bet that this is anomalous activity and should be investigated. In addition, limiting matches based on a maximum file size is a best practice, due to the probably of these offsets occurring randomly in streaming content.
Further, Fidelis Network decodes and identifies all files over all protocols and ports. This detection logic can be used in a YARA content fingerprint that specifies the JPEG file type. With this rule, Fidelis will check all jpeg files for any of the base64 offsets and alert if they appear more than 25 times in a single file.
Citations:
- ^Title. (2023) The Metadata in JPEG files – Exiv2. Retrieved November 21, 2023, from https://dev.exiv2.org/projects/exiv2/wiki/The_Metadata_in_JPEG_files
- ^Selecting Its Name. (2023) CyberChef. Retrieved November 21, 2023, from https://gchq.github.io/CyberChef/
- ^Base64 – Wikipedia. (2023) Retrieved November 21, 2023, from https://en.wikipedia.org/wiki/Base64
- ^Writing YARA rules — yara 4.4.0 documentation. Retrieved November 22, 2023, from https://yara.readthedocs.io/en/stable/writingrules.html#base64-strings



